Cookbook for preparing your own assistant for meetings
Hi folks I want to tell you how you can make your own assistant based on IRIS and OpenAI (perhaps you can then move to your own AI models) iris-recorder-helper This is the first time I have fully tried developing an application for IRIS and I want to point out steps that may also be useful to you Deploy to google cloud via github workflows (One container with an IRIS database and a web server in Python (flask)) and placing secrets inside the application not through an environment variable Record audio from the browser and send to the server Launching cron jobs via the ZPM module Integration with OpenAi First, about the application itself You can try it using the link and see how it works - https://iris-recorder-helper.demo.community.intersystems.com/ Here are the main scenarios to use You can record offline meetings by opening the page on your phone You can record an online meeting by also opening the site on your phone and turning on the sound After you make an entry, you can process it with your prompts Make a summary Highlight agreements on who should do what Find dates and promises Now about the problems that I got 1) Deployment The basic deployment, which is here, is great for a simple application, but I needed to put my secrets in the application itself (not through the environment) For this I made a modification to the github workflow ... - name: Build and Push image run: | echo "${ secrets.CONFIG_BASE64 }" > ./rh/flask/app/config.b64 docker buildx build -t ${GCR_LOCATION}/${PROJECT_ID}/${IMAGE_NAME}:${GITHUB_SHA} --push . - name: Deploy to Cloud Run ... In my repository you can find an example in Python that converts the config from the config.json file to base64Please note that base64 is used to bypass problems with "line breaks" and other special characters You can also use secrets https://cloud.google.com/run/docs/configuring/services/secrets but the “deployment demo key” does not have permission to create secrets :( Now about the problem with audio recording If you want to send an audio stream to the server in chunks, then the first chunk will arrive perfectly and can be sent for decoding, but subsequent chunks will arrive “broken”, since there are headers at the beginning of the audio file. Therefore, I made my own timer that takes the first part of the audio file and adds it to all subsequent ones (you can see it here) mediaRecorder.ondataavailable = function (e) { if (e.data.size > 0) { if (mediaChunkFirst === null) { mediaChunkFirst = e.data return; } mediaChunks.push(e.data); mediaChunkNum++; console.log('iteration: ', mediaChunkNum); if (mediaChunkNum > 10) { saveAudio(); } } }; //... function saveAudio() { let data = [mediaChunkFirst]; data = data.concat(mediaChunks); mediaChunks = []; mediaChunkNum = 0; const audioBlob = new Blob(data, {type: 'audio/wav'}); const formData = new FormData(); formData.append('content', audioBlob); formData.append('date_created', new Date().toISOString()); formData.append('key', window.session_key); $.ajax({ type: 'POST', // ... Cron I decided to do data cleaning on the demo stand to minimize data leaksTo do this, I used the module iris-cron-task and when calling the /autoclean method in IRIS, a task is added to clear all records older than two daysThe code can be found here @app.route('/autoclean') def autoclean(): from iris_cron import Task import iris task_name = 'iris-recorder-helper-cleaner' task_found = False tasks = Task.get_tasks() for item in tasks: if item['name'] == task_name: task_found = True task_id = 0 if not task_found: task = """import iris iris.sql.exec("DELETE FROM Record WHERE date_created
Hi folks
I want to tell you how you can make your own assistant based on IRIS and OpenAI (perhaps you can then move to your own AI models)
This is the first time I have fully tried developing an application for IRIS and I want to point out steps that may also be useful to you
- Deploy to google cloud via github workflows (One container with an IRIS database and a web server in Python (flask)) and placing secrets inside the application not through an environment variable
- Record audio from the browser and send to the server
- Launching cron jobs via the ZPM module
- Integration with OpenAi
First, about the application itself
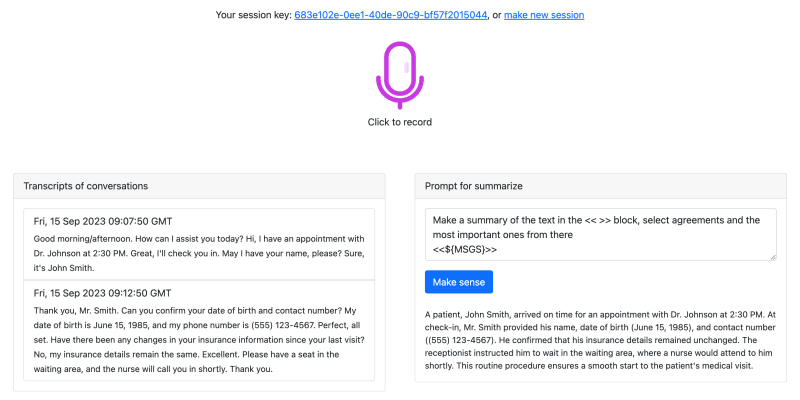
You can try it using the link and see how it works - https://iris-recorder-helper.demo.community.intersystems.com/
Here are the main scenarios to use
- You can record offline meetings by opening the page on your phone
- You can record an online meeting by also opening the site on your phone and turning on the sound
After you make an entry, you can process it with your prompts
- Make a summary
- Highlight agreements on who should do what
- Find dates and promises
Now about the problems that I got
1) Deployment
The basic deployment, which is here, is great for a simple application, but I needed to put my secrets in the application itself (not through the environment)
For this I made a modification to the github workflow
...
- name: Build and Push image
run: |
echo "${ secrets.CONFIG_BASE64 }" > ./rh/flask/app/config.b64
docker buildx build -t ${GCR_LOCATION}/${PROJECT_ID}/${IMAGE_NAME}:${GITHUB_SHA} --push .
- name: Deploy to Cloud Run
...In my repository you can find an example in Python that converts the config from the config.json file to base64
Please note that base64 is used to bypass problems with "line breaks" and other special characters
You can also use secrets https://cloud.google.com/run/docs/configuring/services/secrets but the “deployment demo key” does not have permission to create secrets :(
Now about the problem with audio recording
If you want to send an audio stream to the server in chunks, then the first chunk will arrive perfectly and can be sent for decoding, but subsequent chunks will arrive “broken”, since there are headers at the beginning of the audio file. Therefore, I made my own timer that takes the first part of the audio file and adds it to all subsequent ones (you can see it here)
mediaRecorder.ondataavailable = function (e) {
if (e.data.size > 0) {
if (mediaChunkFirst === null) {
mediaChunkFirst = e.data
return;
}
mediaChunks.push(e.data);
mediaChunkNum++;
console.log('iteration: ', mediaChunkNum);
if (mediaChunkNum > 10) {
saveAudio();
}
}
};
//...
function saveAudio() {
let data = [mediaChunkFirst];
data = data.concat(mediaChunks);
mediaChunks = [];
mediaChunkNum = 0;
const audioBlob = new Blob(data, {type: 'audio/wav'});
const formData = new FormData();
formData.append('content', audioBlob);
formData.append('date_created', new Date().toISOString());
formData.append('key', window.session_key);
$.ajax({
type: 'POST',
// ...Cron
I decided to do data cleaning on the demo stand to minimize data leaks
To do this, I used the module iris-cron-task and when calling the /autoclean method in IRIS, a task is added to clear all records older than two days
The code can be found here
@app.route('/autoclean')
def autoclean():
from iris_cron import Task
import iris
task_name = 'iris-recorder-helper-cleaner'
task_found = False
tasks = Task.get_tasks()
for item in tasks:
if item['name'] == task_name:
task_found = True
task_id = 0
if not task_found:
task = """import iris
iris.sql.exec("DELETE FROM Record WHERE date_created <= DATEADD(DAY, -2, CURRENT_TIMESTAMP)")
"""
tid = iris.ref(0)
command = f'w ##class(%SYS.Python).Run("{task}")'
# 0 0 6 * * * - at 6 am every day
iris.cls('dc.cron.task').Start(task_name, '0 0 6 * * *', command, True, tid)
task_id = tid.value
return f"Task id: {task_id}", 200
Integration with openai
in fact, everything is very simple here, I used a ready-made library (pip install openai) and the whole process consists of a few lines
@app.route('/save', methods=['POST'])
def save():
try:
file_content = request.files['content']
date_created = datetime.strptime(request.form['date_created'], '%Y-%m-%dT%H:%M:%S.%fZ')
rec = Record(key=request.form['key'],
content=file_content,
text=None,
filepath=None,
date_created=date_created)
db.session.add(rec)
db.session.commit()
tmp_file = NamedTemporaryFile(suffix=".wav")
file_content.save(tmp_file)
with open(tmp_file.name, "rb") as tmp_file_audio:
transcript = openai.Audio.transcribe("whisper-1", tmp_file_audio)
if transcript.text:
rec.text = transcript.text
db.session.commit()
result = [{'id': rec.id, 'key': rec.key,
'date_created': rec.date_created,
'text': rec.text}]
return jsonify(result)
except Exception as e:
return f'Error: {str(e)}', 500
and also subsequent processing of all messages via prompt
@app.route('/summary', methods=['POST'])
def summary():
try:
key = request.form['key']
prompt = request.form['prompt']
if key is None:
return jsonify({'message': 'key is empty'}), 400
if prompt is None:
return jsonify({'message': 'prompt is empty'}), 400
records = Record.query.filter_by(key=key).order_by(Record.date_created).all()
msgs = ''
if records:
for record in records:
if record.text:
msgs += "\n" + record.text
else:
raise "Msgs is empty"
prompt = prompt.replace("${MSGS}", msgs)
"""
print('PROMPT:', prompt)
response = openai.Completion.create(
model="text-davinci-003",
prompt=prompt,
temperature=JSON_CONFIG['OPENAI_MAX_TEMP']
)
print(response)
"""
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "user", "content": prompt},
],
)
print(response)
msg = response["choices"][0]["message"]["content"].strip()
return jsonify({"msg": msg})
except Exception as e:
return f'Error: {str(e)}', 500
Thank you for reading to the end, I will be glad to receive your feedback.
What's Your Reaction?